게시판 만들기를 하면서 기계처럼 붙이고 보는 @Transactional을 왜 사용하는지 머릿속에 정리가 안 돼서 다시 강의를 보면서 정리를 해봤다.
데이터베이스를 사용하는 중요한 이유는 하나는 트랜잭션이라는 개념을 지원하기 때문인데 트랜잭션이란 하나의 논리적인 작업 단위로 계좌이체로 예를 들면 돈을 보내고 받는 과정이 하나의 작업이 되는 것이다. 작업이 성공적으로 끝나면 커밋(commit), 중간에 실패하면 되돌리는 롤백을 한다.
트랜잭션은 ACID를 보장해야 하는데 이 중에서 격리성(Isolation)은 동시성의 정도를 나타내는데 동시성을 보장하는 것은 성능과의 trade-off가 있어서 격리 수준이 나뉘게 된다.
[DB 접근 기술1] 트랜젝션(Transaction) 기초
트랜젝션 데이터를 저장할 때 단순 파일이 아닌 데이터베이스에 저장하는 가장 큰 이유는 데이터베이스가 트랜젝션이라는 개념을 지원하기 때문이다. 트랜젝션은 데이터베이스에서 하나의 거
treecode.tistory.com
[Real MySQL] MySQL의 격리 수준
트랜잭션의 격리 수준이란 여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지를 결정하는 것이다. 격리 수준 READ U
treecode.tistory.com
트랜잭션을 사용하기 위해서는 auto commit을 false로 설정하면 되는데 일반적으로는 디폴트 값이 true로 되어 있다. 이렇게 되면 매번 쿼리마다 자동으로 커밋이 되다 보니 하나의 작업 단위를 묶을 수가 없어서 auto commit 옵션을 false로 주고 개발자가 직접 commit, rollback을 해야 된다.
커넥션 연결을 하게 되면 데이터베이스 내부에 세션이 생성되고 세션을 통해서 트랜잭션을 시작하고 SQL을 실행, 커밋, 롤백, 트랜잭션 종료와 같은 작업이 이루어진다.
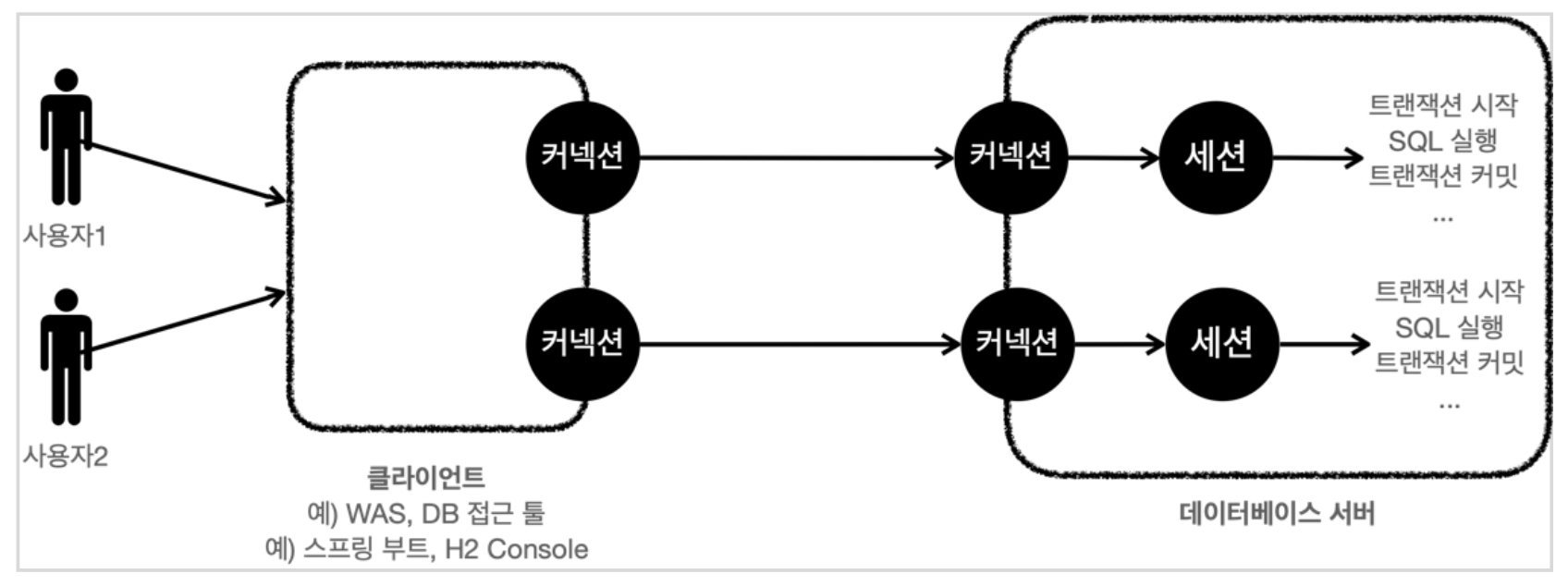
하나의 논리적인 작업 단위의 기준은 비즈니스 로직으로 서비스 계층에서 시작을 해야 하는데 이렇게 되면 서비스 클래스에서 커넥션을 꺼내기 위해 DataSource를 가지고 트랜잭션 시작, commit, rollback, 트랜잭션 종료 등의 처리를 하는 코드가 들어가게 된다.
public void accountTransfer(String fromId, String toId, int money) throws
SQLException {
Connection con = dataSource.getConnection();
try {
con.setAutoCommit(false); //트랜잭션 시작 //비즈니스 로직
bizLogic(con, fromId, toId, money); con.commit(); //성공시 커밋
} catch (Exception e) { con.rollback(); //실패시 롤백
throw new IllegalStateException(e);
} finally {
release(con);
}
}위의 예시에서 bizLogic()에서는 트랜잭션을 유지하기 위해 동일 커넥션을 사용해야 되고 repository를 호출할 때마다 커넥션을 파라미터로 전달해줘야 한다. 그리고 SQLException 같이 JDBC 전용 예외 같은 구체화에 의존성이 생기는 등 JdbcTempalte, JPA .. 데이터 접근 기술의 변경에 영향을 받게 된다.
스프링은 이러한 문제를 해결하기 위해 트랜잭션 추상화 인터페이스 TransactionManager를 제공하는데 트랜잭션 추상화, 커넥션 동기화 역할을 대신해 준다.
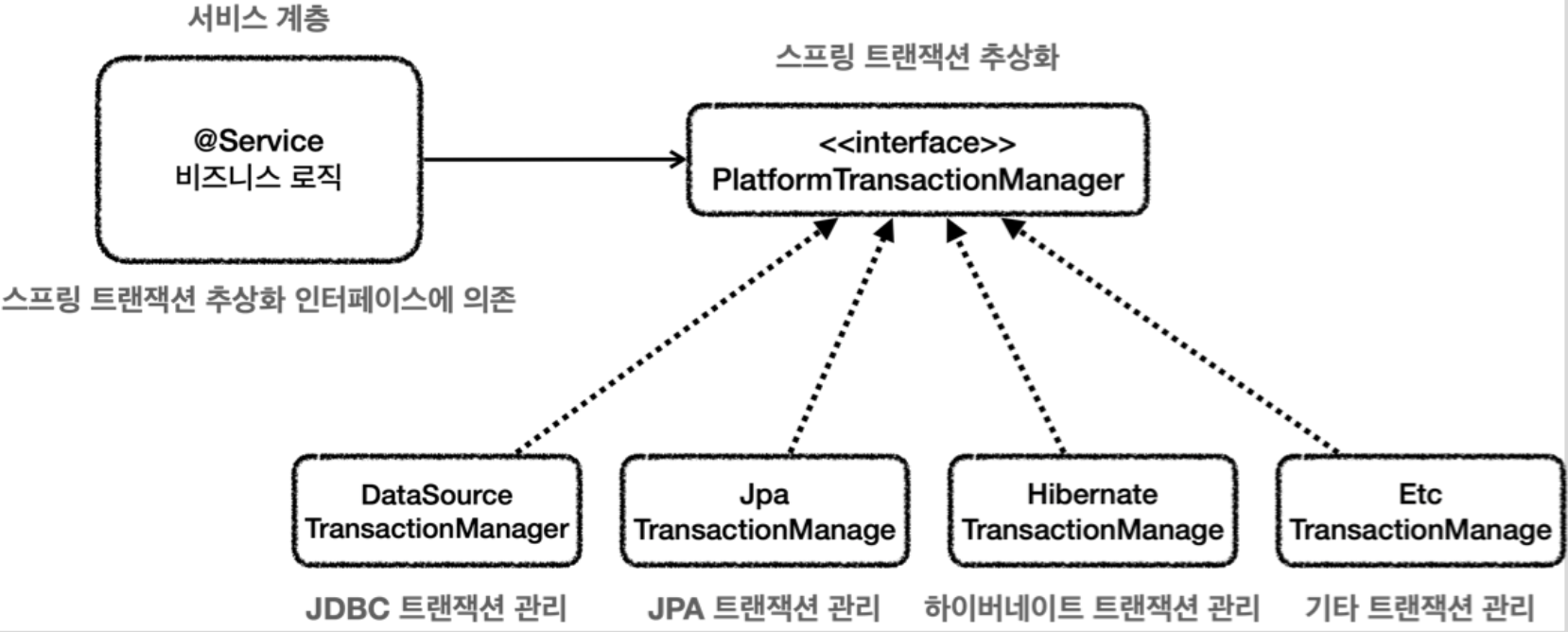
커넥션은 트랜잭션 동기화 매니저가 스레드별 저장소인 스레드 로컬을 통해 동기화를 해서 파라미터로 전달하지 않아도 유지할 수 있다. 스레드 로컬은 사용 후 정리하는 것이 매우 중요하기 때문에 (+ 커넥션 반납 등) 개발자가 직접 하기보다는 제공되는 기술을 사용하는 것이 안전하다.
트랜잭션 매니저를 사용해도 커밋, 롤백 try-catch를 하는 코드가 남아있는데 스프링 AOP를 활용한 @Transactional을 사용하면 깔끔하게 처리가 가능해진다.
@Transactional을 정확히 이해하려면 스프링 AOP를 학습해야 되는데 일단은 왜 써야 하는지 정도만 알고 넘어갔다.
@Transactional을 클래스에 메서드에 사용하면 트랜잭션 AOP는 프록시를 만들어 스프링 컨테이너에 등록하는데 이 프록시가 트랜잭션을 관리하는 로직을 대신 처리해 주게 된다.
한 가지 주의점은 외부에서 요청을 하면 프록시 객체가 요청을 먼저 받아서 트랜잭션을 처리하고, 실제 메서드를 호출해 주는데 만약 내부에서 메서드를 호출하는 경우 프록시를 거치지 않아서 트랜잭션이 적용되지 않는 문제가 생긴다.

이전에는 클래스에 @Transactional을 readOnly 설정으로 두고 데이터 삽입, 수정, 삭제 메서드만 따로 @Transacional을 선언해서 사용을 해서 그런지 이런 위험 요소를 인식하지 못했다.
클래스에 @Transactional을 선언하는 경우 트랜잭션이 의도하지 않은 곳까지 과도하게 적용이 돼서 메서드 단위로 적용을 한다. 트랜잭션은 주로 비즈니스 로직의 시작점에 걸기 때문에 외부에서 열어둔 곳을 시작점으로 해서 클래스에 @Transactional 애노테이션을 선언해도 public 메서드에만 적용이 된다.
추가적으로 스프링 트랜잭션 AOP는 예외의 종류에 따라 트랜잭션을 커밋하거나 롤백하는데 RuntimeException , Error와 그 하위 예외가 발생하면 롤백, 체크 예외와 그 하위 예외가 발생하면 커밋을 한다. (@Transactional에서 rollbackFor 옵션으로 변경 가능)
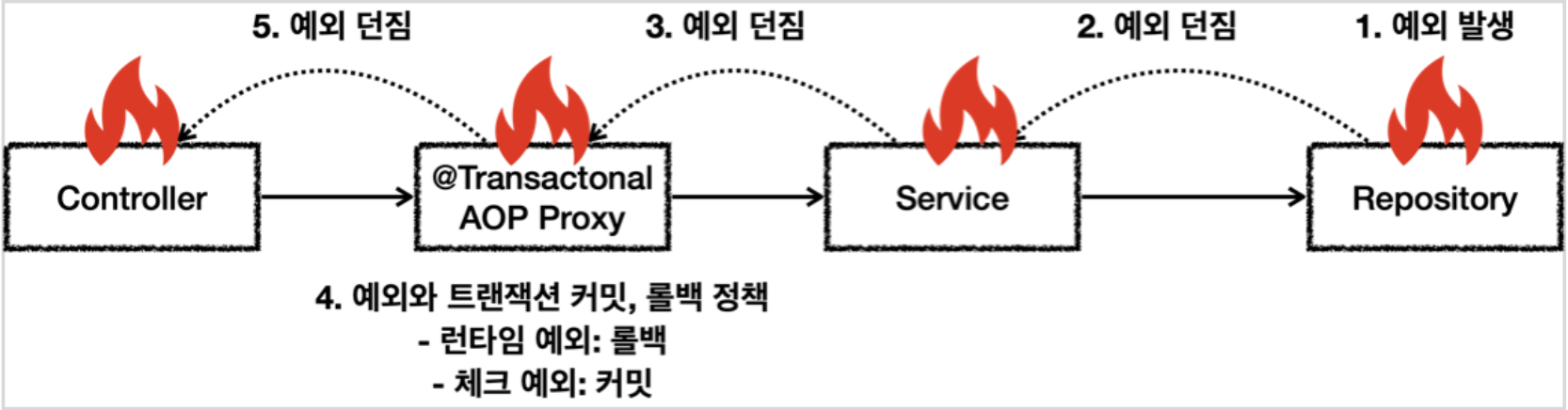
체크 예외의 경우 비즈니스적인 예외 상황에서 주로 사용한다고 하는데 예를 들면 회원의 주문 Order에서 잔고 부족의 경우 일단 커밋을 하고 추가 결제를 하도록 할 수도 있다. (생각해 보니 체크 예외는 사용한 적이 없는 거 같은데 중요한 비즈니스 예외 상황에서 사용하면 좋을 것 같다.)
간단 정리
@Transactional 사용하는 이유
- 애플리케이션에서 트랜잭션 관리
- 비즈니스 로직과 관련 없는 중복 코드 제거
- 예외 전파, 관리
JdbcTemplate은 템플릿 콜백 패턴을 사용해서 JDBC를 직접 사용할 때 발생하는 대부분의 반복 작업을 대신 처리해 준다.
- 커넥션 획득, 종료, statement, resultset 종료
- 트랜잭션을 다루기 위한 커넥션 동기화
- 예외 발생 시 스프링 예외로 변환
JdbcTemplate에서 tryForStream() 메서드를 사용하면 예외적으로 직접 리소스 종료를 해줘야 하는데 그렇지 않을 경우 커넥션 반납이 되지 않는 문제가 생긴다. 같이 공부하는 분이 커넥션 반납이 되지 않는다고 물어보셨을 때 @Transactional 역할을 잘 알고 있었으면 이 부분을 먼저 확인해 봤을 거 같은데 금붕어처럼 다 까먹고 말똥말똥 쳐다보고 있었다. @Transactional을 사용하면 트랜잭션 기능 외에도 DB 접근 기술마다 커넥션이 종료되지 않는 상황에서 안전하게 처리를 해주는 이점도 있는 것 같다.
[참고]
인프런 김영한님 DB 접근 기술 1,2편
'Spring' 카테고리의 다른 글
| [Spring] IntelliJ 디버깅시 JPA 지연 로딩(Lazy Loading) 주의점 (0) | 2023.12.03 |
|---|---|
| [Spring] 커스텀 Validator 적용 (ConstraintValidator) (0) | 2023.11.27 |
| [Spring] 댓글 더보기 기능 구현 (LIMIT) (0) | 2023.04.28 |
| Servlet과 Servlet Container (5) | 2023.03.25 |
| [Spring Boot] 스프링 시큐리티 OAuth2.0 로그인 (KAKAO) (0) | 2023.02.15 |