자바로 WAS를 구현해 보았는데 사실 이번 미션은 HTTP와 WAS에 대해 공부하는 것인데 스프링 MVC 구조에 집중해서 조금 아쉬웠다.
프록시 패턴에 대해 간단 정리
처음에는 컨트롤러에서 여러 메서드를 핸들링하려고 하다 보니 컨트롤러에 요청을 받는 public 메서드와 각각의 처리(회원가입, 유저 조회 등)를 하는 private 메서드를 만들어야 했다. 그래서 내 맘대로 프록시라는 클래스를 만들고 Enum으로 매핑을 해주었다.


이렇게 컨트롤러에 메서드를 추가할때마다 프록시와 Enum 클래스를 수정하는 이상한 코드가 완성이 되었다. 내가 원하는 것은 컨트롤러에 메서드만 추가하면 동작이 되는 것이었기 때문에 결국 김영한님의 스프링 고급편 강의로 어설프게 들어본 프록시 패턴과 리플렉션에 대해 공부를 해보았다.
프록시 패턴은 접근 제어, 캐싱, 부가 기능(데코레이트) 등의 목적으로 사용이 된다. GOF 디자인 패턴에서는 의도에 따라 프록시 패턴과 데코레이터 패턴으로 나누는데 프록시 패턴은 접근 제어가 목적이고, 데코레이터 패턴은 새로운 기능 추가가 목적이다.
이전에 Redis로 캐싱을 할 때 @Cacheable로 간단하게 캐싱을 했었는데 스프링부트는 애노테이션으로 프록시 AOP 기술을 쉽게 사용할 수 있게 해 준다. 아래 예시는 공식 문서에서 @Transactional을 예시로 들었는데 @Transactional 애노테이션을 사용하면 프록시가 트랜잭션 관련 처리를 해준다. 프록시와 실제 비즈니스 로직이 있는 AccountServiceImpl이 같은 AccountService를 구현하고 있는 것을 볼 수 있다.
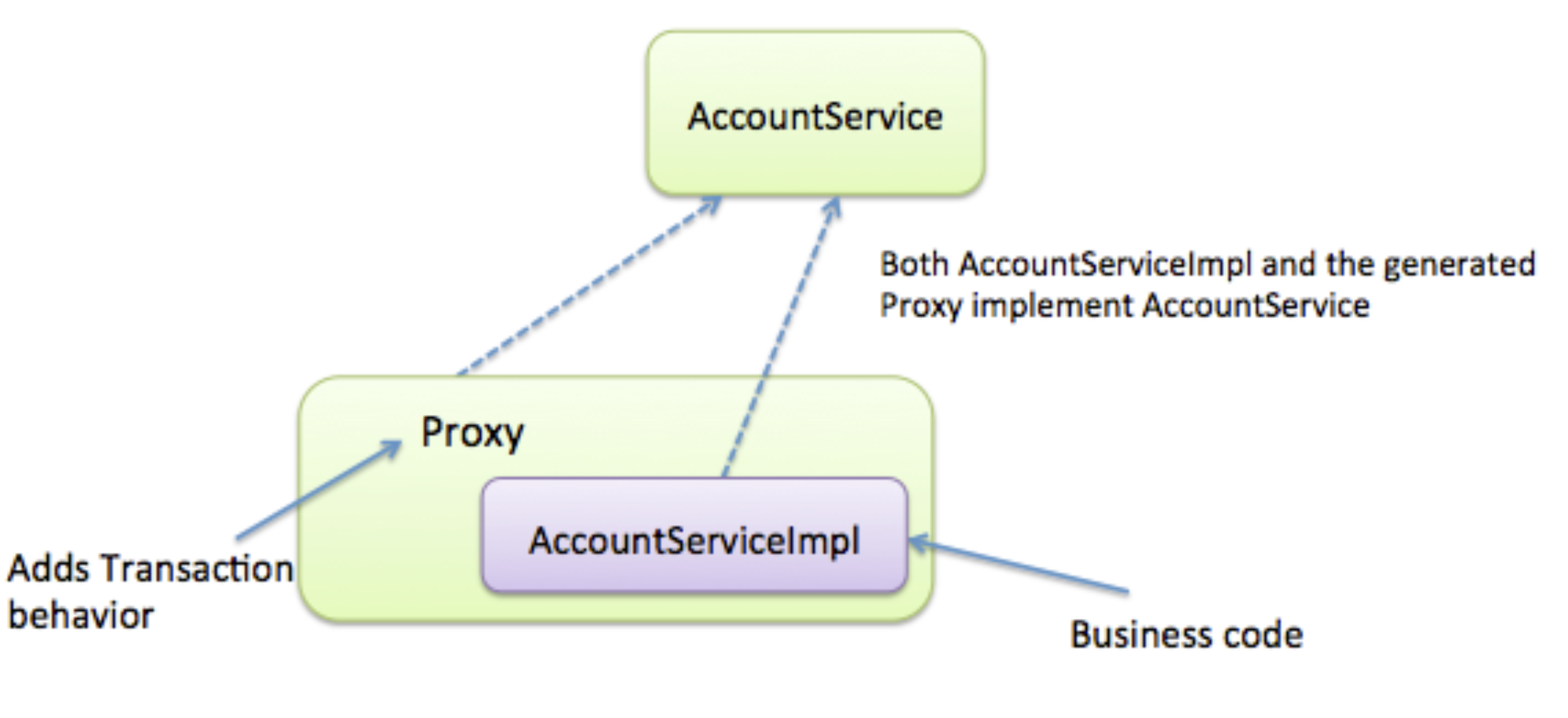
프록시와 대상은 다형성으로 호출하는 쪽에서는 프록시를 호출한 것인지 실제 대상을 호출한 것인지 몰라야 된다.

인터페이스 대신 부모 상속으로도 가능하지만 결국 프록시 클래스를 계속 직접 만들어야 되는 것은 변하지 않는다. JDK 동적 프록시는 InvocationHandler를 통해 동적으로 프록시를 생성할 수 있지만 인터페이스가 필요하다는 조건이 있고 CGLIB를 사용하면 인터페이스가 없이도 동적 프록시를 생성할 수 있다고 한다.
결국 디자인 패턴은 의도가 중요하다고 하는데 아직 디자인 패턴을 깊게 볼 때는 아닌것 같고 현재 나는 요청을 전달하고 싶은 것뿐이라서 @RequestMapping 애노테이션을 만들고 리플렉션으로 요청에 맞는 컨트롤러와 메서드를 찾아서 실행(invoke)해주는 방향으로 전환했다.
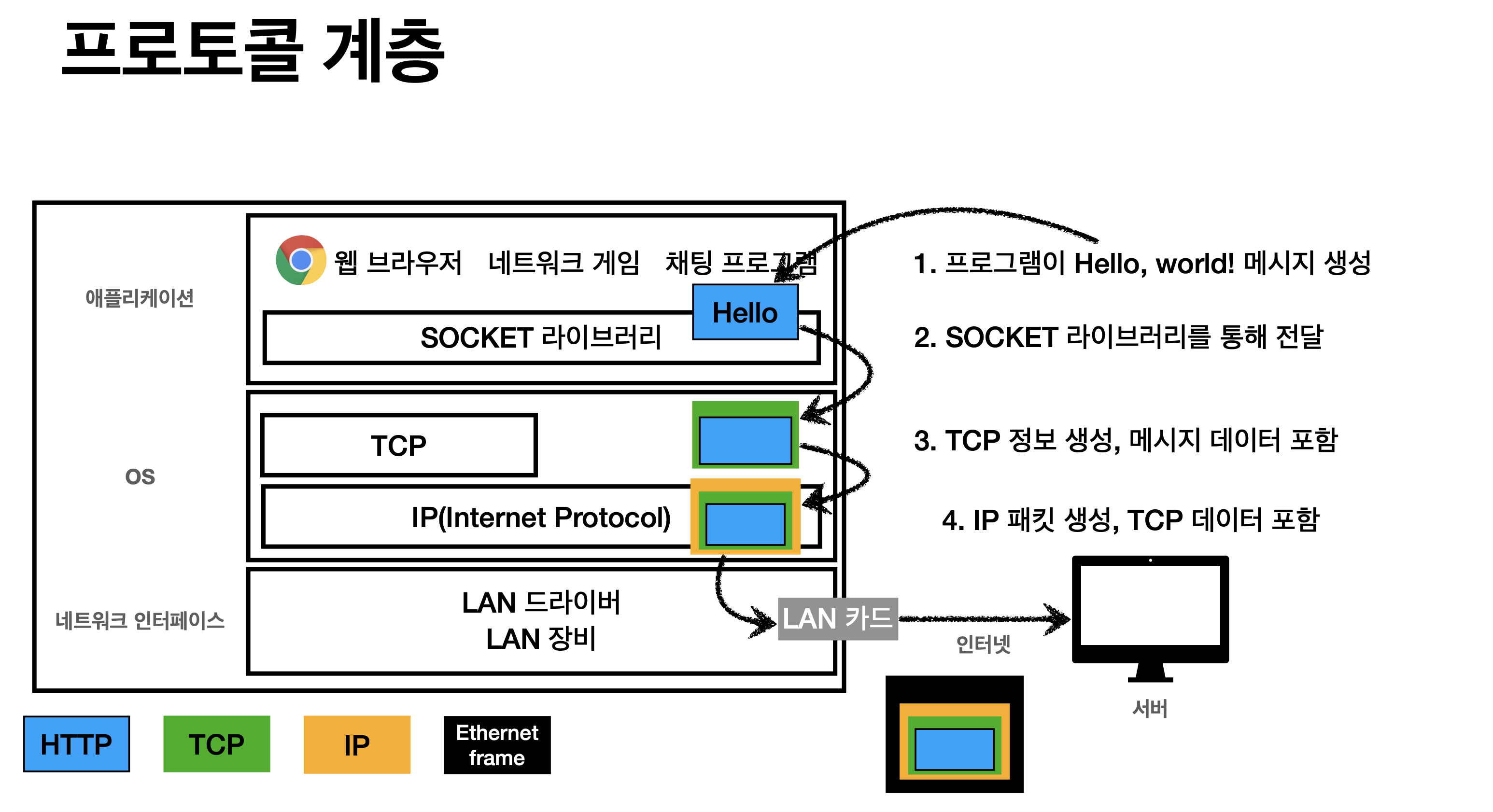
전체적인 흐름은 아래와 같은데 템플릿 엔진은 구현하지 못했다.


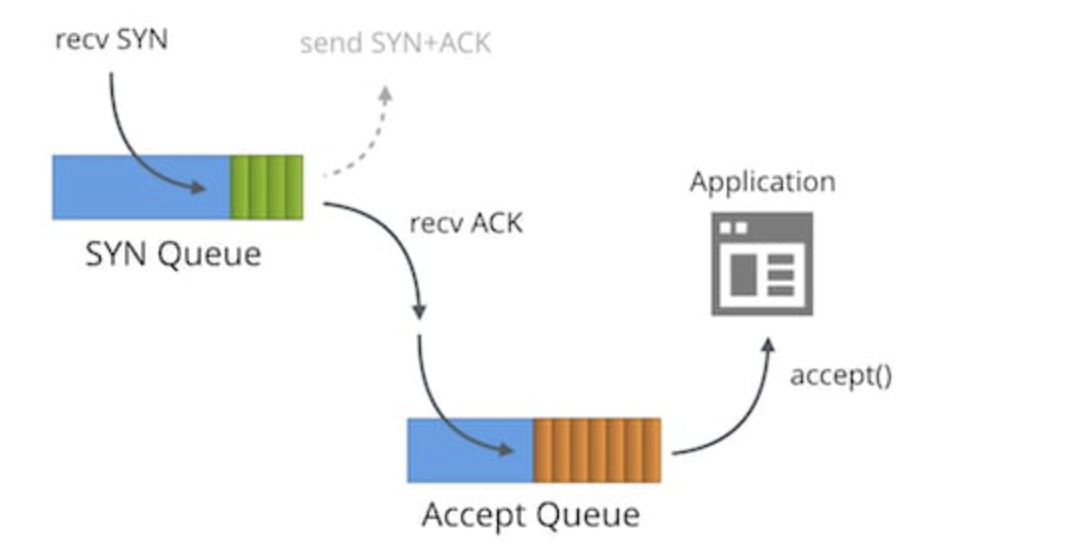
먼저 동시에 여러 요청을 처리하기 위해 ThreadPool을 생성하고 serverSocket에서 accept()를 한다.
accept() 호출 시 메인 스레드는 block 상태가 되고 연결이 되면 생성한 소켓(connect)을 반환해서 스레드풀로 비동기 처리를 한다.

정리하면서 알았는데 executorService.shutdown()이 호출되면 새로운 작업은 실행하지 않고 현재 실행중인 작업만 처리한다.
하지만 실행중인 작업이 종료가 될 때까지 blocking 하지 않기 때문에 실행 중인 작업까지 처리하기 위해서는 awaitTermination(), shutdownNow()를 활용해서 종료해야 한다.
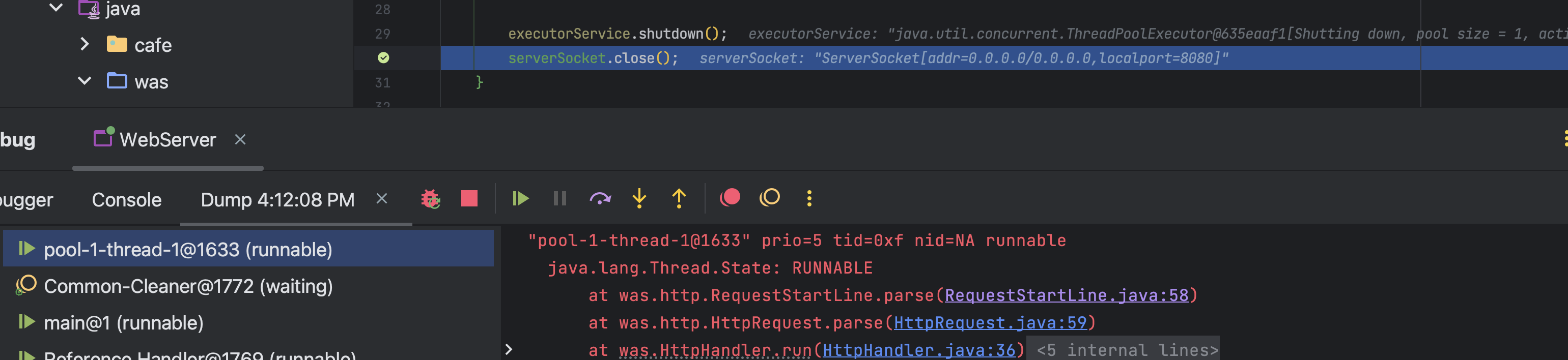
HttpHandler는 Http 요청, 응답을 처리하는 핸들러로 request를 파싱해서 handle()로 보낸 뒤 response가 담긴 결과를 sendResponse()로 보낸다.

handle()은 RequestUrl의 확장자를 통해 정적 리소스 요청인지, 동적 리소스 요청인지 체크한다. 동적 요청의 경우 싱글톤으로 생성한 DispatcherServlet을 가져와서 doDispatch()를 실행한다. HttpHandler는 요청당 생성이 되고 DispatcherServlet을 관리하는 별도의 컨테이너가 없어서 싱글톤으로 생성을 했다.
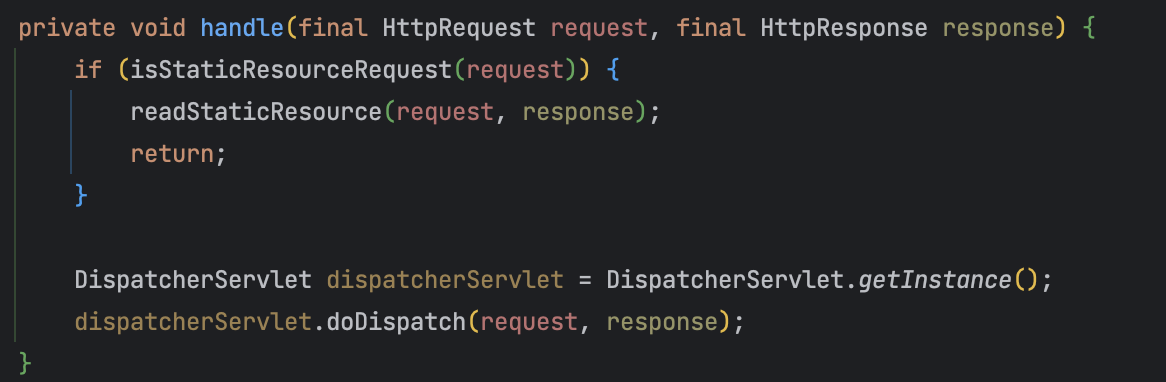
doDispatch()는 ControllerAdapter에서 handle()을 통해 컨트롤러에게 요청을 전달해서 처리하고 ModelAndView를 반환받는다.
(예외처리나 리다이렉트 처리 부분은 필터를 적용하면 좋을 것 같은데 구현을 못했다.)

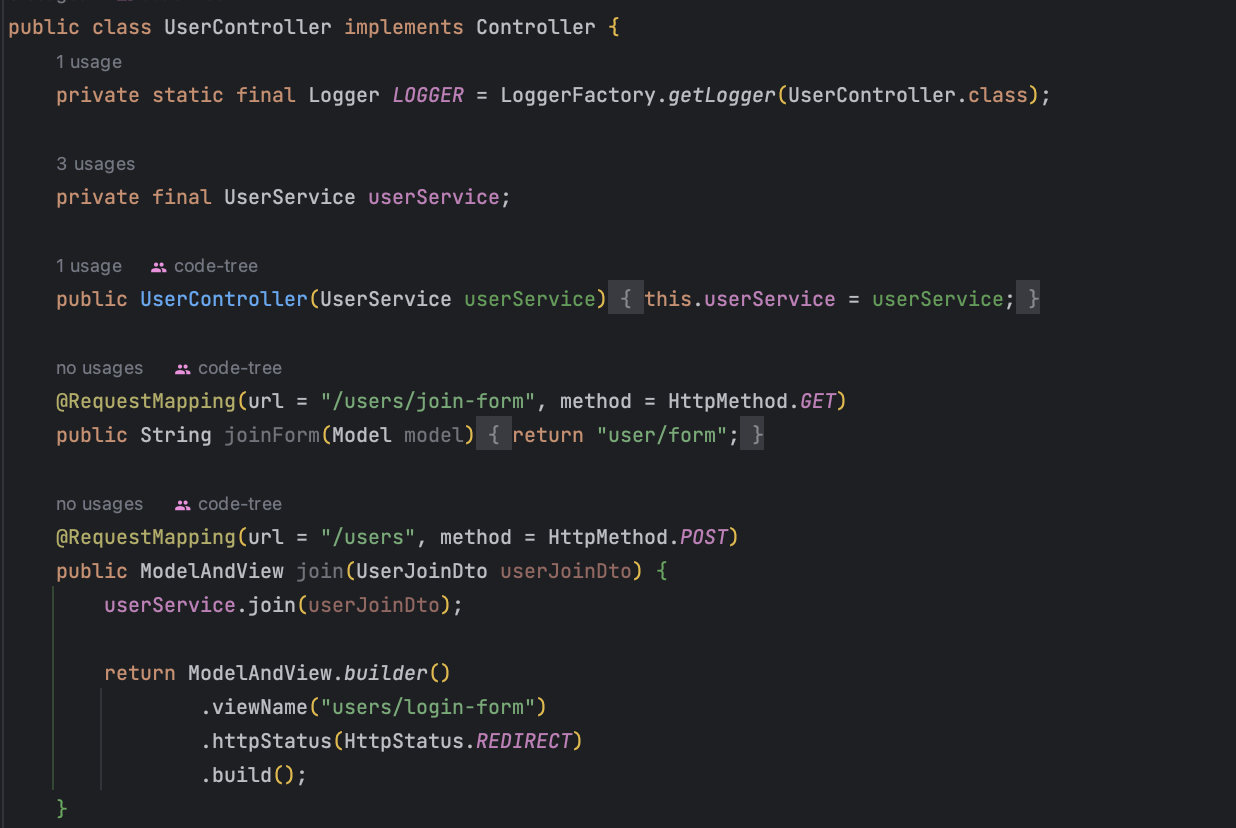
ControllerAdapter는 Controller 클래스들의 @RequestMapping 정보를 읽어서 요청을 처리할 수 있는 Controller를 찾는 역할을 한다. findAllMappingUrl()은 컨트롤러의 @RequestMapping 매핑 정보를 초기화하기 위해 사용한다

다시 ControllerAdapter의 handle() 메서드를 보면
1. findController: 요청을 처리할 수 있는 컨트롤러를 찾고
2. findControllerMethod: 해당 컨트롤러의 메서드를 찾는다.
3. ArgumentResolver를 통해 메서드를 실행하기 위해 필요한 파라미터를 resolve 한다.
4. 메서드 실행에 필요한 arguments를 만들어서 메서드를 실행(invoke)한다.
5. 메서드의 반환값으로 ReturnValueHandler를 통해 ModelAndView를 생성한다. (ViewName, Json Convert 등 처리)

MethodArgumentResolver는 인터페이스로, Argument 타입에 따라 나뉘는데 ObjectArgumentResolver는 ObjectBinder를 사용해서 QueryParameter를 객체로 바인딩해 준다.

ObjectBinder는 기본 생성자와 setter를 필요로 한다. setter를 호출하기 위해 setName, setAge와 같은 setter 메서드명을 직접 만들어야 하는데 컴파일 에러가 뜨는 것도 아니라서 위험하다.
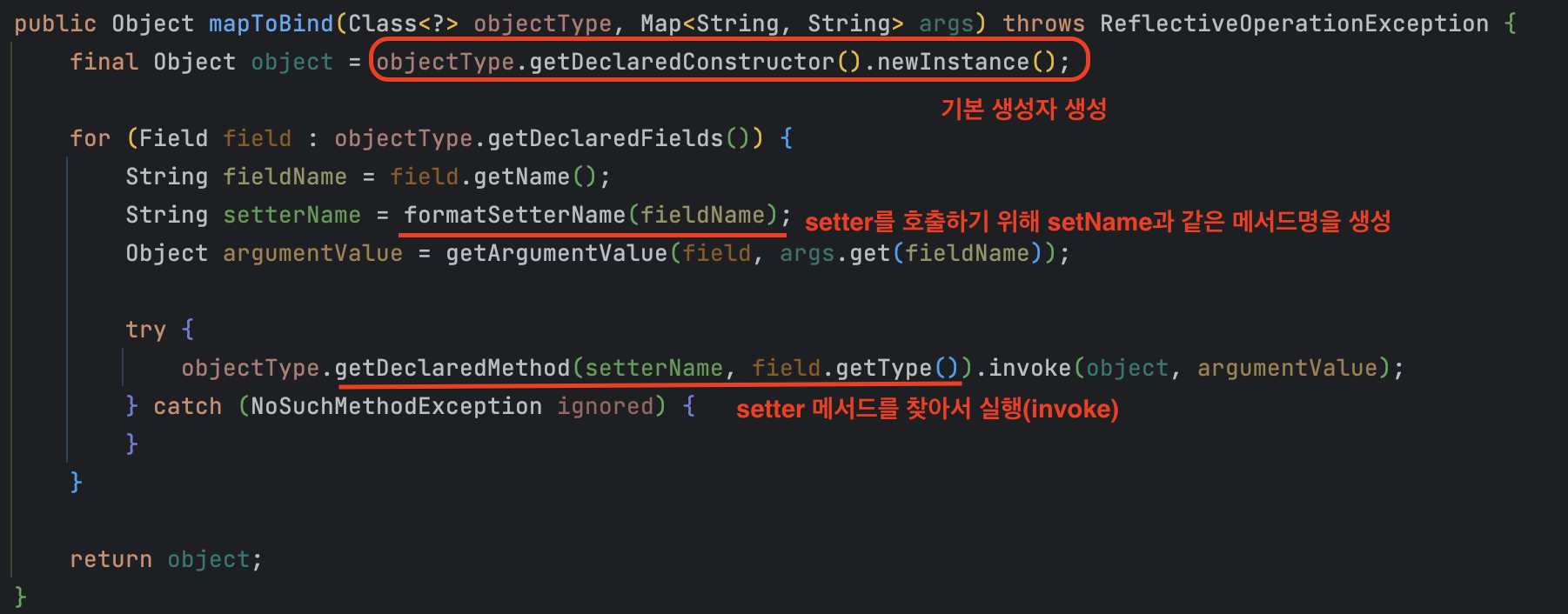

MessageBody 처리는 MessageConverter를 사용하는데 원래는 ObjectBinder라는 클래스가 없었지만 여기서도 ObjectBinder 기능이 필요하기 때문에 따로 클래스로 만들게 되었다. (form-data만 파싱만 구현했다.)

다시 DispatcherServlet의 doDispatch()로 돌아와서 ViewResolver를 통해 View를 찾고 렌더링을 하면 HttpHandler에서 Response 응답을 스트림으로 보낸다. 맨처음 말한것처럼 HTTP 헤더를 제대로 처리하지 못해서 아쉽다.

결과적으로 Controller에서는 어느 정도 의도한 대로 동작을 할 수 있게 되었다. @Valid로 컨트롤러 파라미터의 객체 생성 시 validation을 하는 경우에도 ArgumentResolver가 동작해서 BindingResult에 담아주는데 간단하게나마 구현을 해보니 어떤 식으로 동작이 되는지 이해할 수 있었다. 여전히 새로운 컨트롤러를 생성하는 로직을 추가해야 되는데 이 부분은 DI 컨테이너를 구현해야 될 것 같다.
[참고]
김영한님 스프링 고급편
[Spring] @Valid와 @Validated를 이용한 유효성 검증의 동작 원리 및 사용법 예시 - (1/2)
Spring으로 개발을 하다 보면 DTO 또는 객체를 검증해야 하는 경우가 있습니다. 이를 별도의 검증 클래스로 만들어 사용할 수 있지만 간단한 검증의 경우에는 JSR 표준을 이용해 간결하게 처리할 수
mangkyu.tistory.com
Transactions, Caching and AOP: understanding proxy usage in Spring
In the Spring framework, many technical features rely on proxy usage. We are going to go in depth on this topic using three examples: Transactions, Caching and Java Configuration. All the code samples shown in this blog entry are available on my github acc
spring.io
[Java] ExecutorService.shutdown(Now) & awaitTermination
헷갈리는 ExecutorService 의 종료와 관련된 메소드를 테스트해봤다.
velog.io
'Java' 카테고리의 다른 글
| [Java] 자바로 간단한 웹서버 구현 1 (0) | 2023.06.03 |
|---|---|
| [Java] 멀티 스레드 환경에서 HashMap 동시성 문제 해결 (0) | 2023.04.02 |
| [Java] HashMap 구조 (0) | 2023.03.27 |
| [Java] System.in 테스트 하는 방법 (0) | 2023.03.11 |
| [Java] static import 주의점 (0) | 2022.10.13 |