Optional<T>은 제네릭 클래스로 T 타입의 객체를 감싸는 Wrapper 클래스이다. 최종 연산의 결과를 Optional 객체에 담아서 반환하면 반환된 결과가 null인지 체크할 필요 없이(NullPointerException의 위험 없이) 간단하고 안전하게 사용할 수 있다. (자바의 정석 p835)
1. Optional 객체를 생성할 때는 of() 대신 ofNullable()을 사용
Optional을 사용하는 방법과 주의 사항을 간단하게 정리하면 먼저 Optional 객체를 생성할 때는 of() 또는 ofNullable()을 사용한다.
말 그대로 Nullable은 null을 허용하기 때문에 참조변수가 null의 가능성이 있으면 ofNullable()로 생성하는 것이 좋지만 Optional을 사용하는 것 자체가 null이 올 수 있기 때문에 사용하는 것이라 그냥 ofNullable()로 사용하는 것이 좋다.
2. Optional 객체의 값을 가져올 때는 get(), orElse() 대신 orElseGet()을 사용
Optional 객체의 값을 꺼낼 때는 get(), orElse(), orElseGet(), orElseThrow()를 사용하면 되는데 먼저 get()은 값이 null일 경우 NoSuchElementException이 발생하기 때문에 사용하지 않는 것이 좋다.
orElseThrow()는 예외를 던지는 것이니 그렇다 치고 orElse(), orElseGet()은 뭔가 비슷해서 무슨 차이가 있나 찾아보았다.
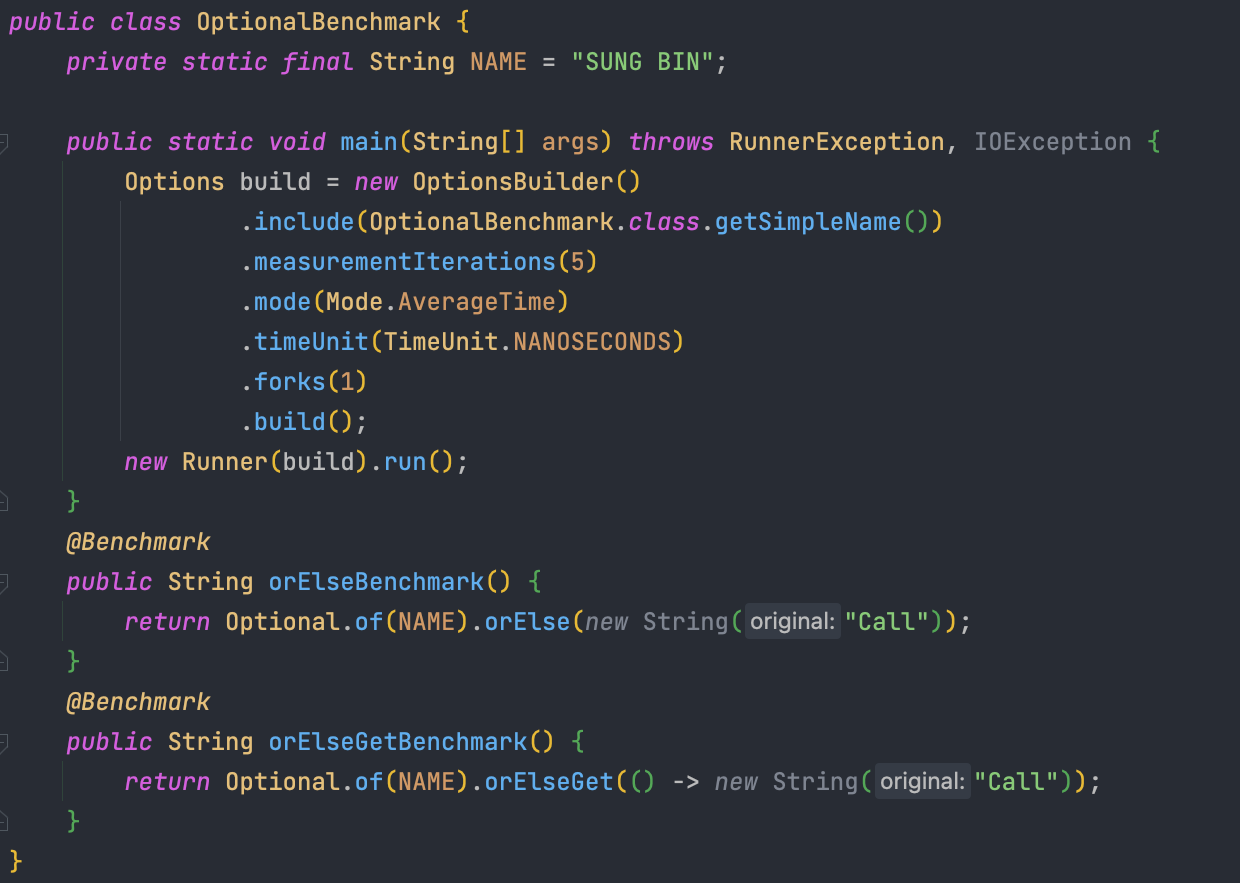
orElse() vs orElseGet()
- orElse(): returns the value if present, otherwise returns other
- orElseGet(): returns the value if present, otherwise invokes other and returns the result of its invocation
설명을 보면 둘다 만약 값이 존재하지 않을때 다른 other를 반환한다고 나와있지만 테스트를 해보면 orElse()의 경우에는 값이 존재할 때도 항상 호출이 된다. null이 아니더라도 계속 객체가 생성되고 있는 것이다. 그리고 메서드가 DB에 저장하는 로직이 있는 경우에는 더 큰 문제가 생길 수 있다. 그래서 성능상 orElseGet()을 사용하는 것이 더 나은 선택이다.
JMH로 간단하게 테스트 해봤는데 계속 이전에 테스트하던거랑 같이 실행이 되서 쩔쩔 메다가 OptionsBuilder()로 급하게 처리했는데 Logger도 뭐가 문제인지 제대로 안 되고 가볍게 해보려던 거에 시간을 많이 쓰니 멘탈이 흔들린다. (ㅠㅠ) 얕게 알면 이래서 위험하다. 다시 공부를 해봐야겠다.

JMH(Java Microbenchmark Harness) 사용법
개발을 진행하다가 보면, 성능문제를 해결해야 하는 경우는 매우 많다. 성능 문제를 해결하기 위해서는 우선 성능을 측정해야하며, 성능을 측정하는 방법와 도구는 셀수도 없이 많다. 대부분의
ysjee141.github.io
자바 Optional: 5. Optional 톺아보기
Optional 클래스를 의도에 맞게 잘 사용하려면 어떻게 해야할까?
madplay.github.io
Java Optional - orElse() vs orElseGet() | Baeldung
Explore the differences between Optional orElse() and OrElseGet() methods.
www.baeldung.com
Optional 과 null 에 대해 ⌥␀
런타임에서 발생하는 NullPointException 방어를 위해 만들어둔 로직체크는 코드의 가독성과 유지 보수성이 떨어진다. 어떻게 null…
tecoble.techcourse.co.kr
'Java' 카테고리의 다른 글
| [Java] 제네릭 개념과 제네릭 메서드 (0) | 2022.10.13 |
|---|---|
| [Java] 추상 클래스와 인터페이스 (0) | 2022.10.04 |
| [Java] 제네릭에서 Raw Type 선언 주의 (이펙티브 자바) (0) | 2022.08.16 |
| [Java] HashMap put() 반환값 (null 조심) (0) | 2022.08.09 |
| [Java] equals() 사용시 주의점 (NullPointerException) (0) | 2022.08.04 |