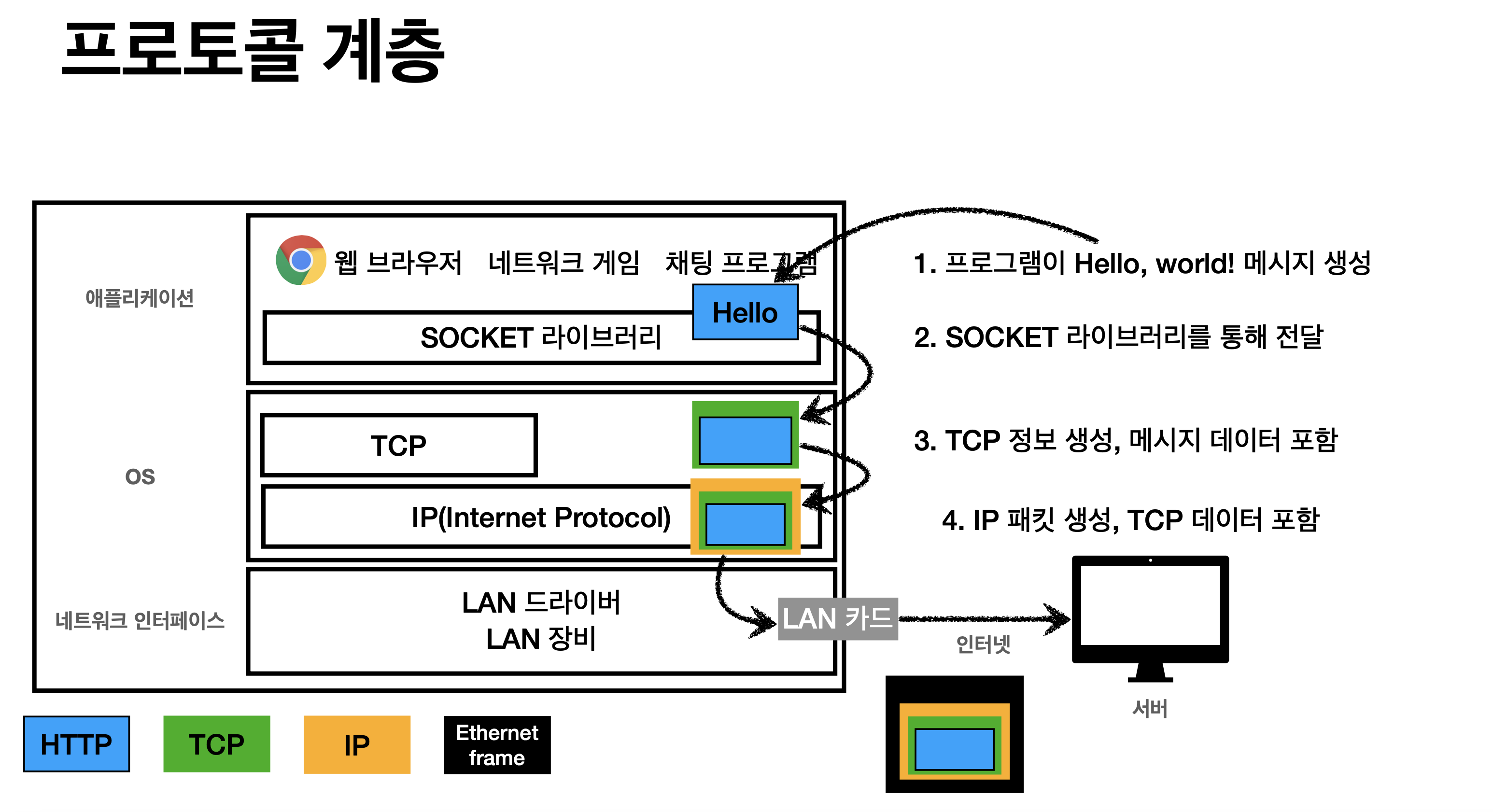
SRS(Spatial REference System)은 익숙한 용어로 좌표계(Coordinate System)라고 생각하면 된다.
SRS는 GCS(Geographic Coordinate System)와 PCS(Projected Coordinate System)로 구분이 된다.
GCS는 지구 구체상의 특정 위치나 공간을 표현하는 좌표계로 위도(Latitude)와 경도(Longitude)와 같은 각도 단위로 표시된다. PCS는 지구를 평면으로 투영시킨 좌표계를 말한다.
목적이나 용도별로 사용하는 지리 좌표가 매우 다양해서 동일 지점이라고 해도 어느 공간 좌표계(SRS)를 사용하느냐에 따라 표시 방법이 달라진다.
SRID(Spatial Reference ID, SRS_ID)는 특정 SRS를 지칭하는 고유 번호로 흔히 사용하는 WGS 84 좌표계의 SRID는 4326이다.
MySQL 8.0부터 SRID 지원이 추가되면서 SRID를 별도로 지정하지 않으면 SRID가 0인 평면 좌표계로 인식이 된다. SRID가 0으로 정의된 컬럼에 WGS 84 좌표계를 참조하는 공간 데이터를 저장하려고 하면 에러가 발생한다. 만약 SRID를 명시적으로 정의하지 않으면 해당 컬럼은 모든 SRID를 저장할 수 있지만 SRID가 제각각이면 인덱스 검색이 불가능하기 때문에 명시하는 것이 좋다. 그리고 MySQL 8.0에서 지원되는 공간 함수들이 모든 SRID를 지원하는 것은 아니기 때문에 잘 보고 선택을 해야 한다.
MySQL의 공간 인덱스(Spatial Index)는 R-Tree 인덱스 알고리즘을 이용해 2차원의 데이터를 인덱싱하고 검색하는 인덱스이다.
내부 메커니즘은 B-Tree와 흡사한데 B-Tree는 인덱스를 구성하는 컬럼의 값이 1차원 scalar 값인 반면, R-Tree는 2차원의 공간 개념 값이다.
MySQL의 공간 확장(Spatial Extension)을 이용하면 지도, 위치 기반의 서비스를 구현하는데 큰 도움이 된다.
Spatial Extension 기능
- 공간 데이터를 저장할 수 있는 데이터 타입
- 공간 데이터의 검색을 위한 공간 인덱스(R-Tree)
- 공간 데이터의 연산 함수(거리 또는 포함 관계의 처리)
공간 데이터 타입
- 공간 정보의 저장 및 검색을 위해 여러 가지 기하학적 도형 정보를 관리할 수 있는 데이터 타입으로 Geometry는 Point, Line, Polygon의 부모 타입이다

MBR(Minimum Bounding Rectangle)이란 공간 데이터 타입의 도형을 감싸는 최소 크기의 사각형을 의미한다. 그리고 MBR의 포함 관계를 B-Tree 형태로 구현한 인덱스가 R-Tree 인덱스다.
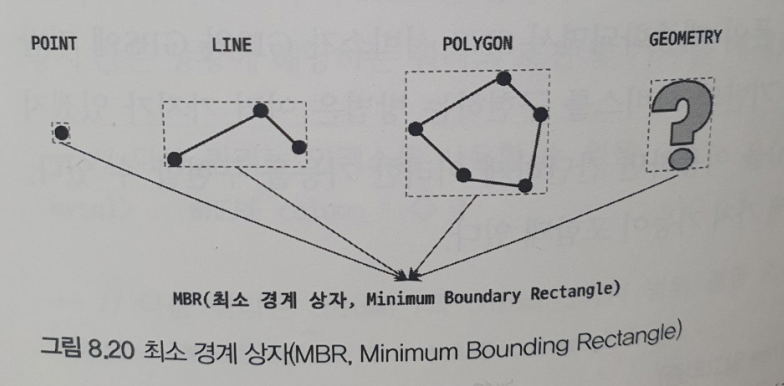
아래 그림을 보면 공간 데이터 도형을 감싸는 MBR이 있고 최소 MBR 사각형들을 그룹 단위로 감싸는 MBR이 있다. 그리고 이러한 MBR을 감싸는 MBR이 있다. 이렇게 공간 데이터의 영역을 포함 관계로 인덱스를 만들면 일정 반경 내의 검색을 인덱스를 활용하여 효율적으로 할 수 있게 된다.


R-Tree 인덱스를 이용하기 위해서는 ST_Contains(), ST_Within() 등과 같은 포함 관계를 비교하는 함수로 검색을 해야 한다. 예제를 찾아보면 ST_Distance(), ST_Distance_Sphere()를 이용한 경우도 보이는데 이 함수는 공간 인덱스를 사용하지 못한다.
열심히 썼는데 글이 날아가서 자세한 부분은 문서를 보고 사용하는 것이 좋을 것 같다 ㅠㅠ
MySQL :: MySQL 8.0 Reference Manual :: 12.16.1 Spatial Function Reference
MySQL 8.0 Reference Manual / ... / Functions and Operators / Spatial Analysis Functions / Spatial Function Reference 12.16.1 Spatial Function Reference The following table lists each spatial function and provides a short description of eac
dev.mysql.com
ST_Buffer()를 사용하면 특정 위치로부터 반경(m)에 해당하는 점들을 반환하는데 ST_Buffer_Strategy()를 추가할 수 있다. 기본 point 전략이 ST_Buffer_Strategy(point_circle, 32)로 조회를 해보면 33개의 좌표로 이루어진 Polygon 타입을 반환한다.
참고로 WGS 84 좌표계는 POINT(위도, 경도)로 입력을 해야 되는데 SRID 값에 따라 POINT(경도, 위도)인 좌표계도 있어서 스펙을 찾아보고 해야 한다.

ST_Buffer()를 통해 범위를 결정하고 ST_Contains() 같은 MBR을 이용해서 포함 관계를 비교하는 함수를 통해 일정 반경 내의 장소들을 검색할 수 있다. 인덱스를 설정하고 더미 데이터를 10000건 정도 넣어서 확인을 해봤는데 range 접근 방식으로 데이터를 읽는 것을 확인할 수 있다.

ST_Distance_sphere() 함수를 사용했을 때는 풀 테이블 스캔을 하기 때문에 주의해야 한다.

[참고]
Real MySQL 8.0
'데이터베이스' 카테고리의 다른 글
| [Real MySQL] 실행 계획 (0) | 2024.01.15 |
|---|---|
| [Real MySQL] 인덱스 (0) | 2023.04.16 |
| [Real MySQL] MySQL의 격리 수준 (0) | 2022.12.03 |
| [Real MySQL] MySQL 아키텍처 (0) | 2022.12.02 |
| [MyBatis] 마이바티스 스프링 연동 모듈 (0) | 2022.07.13 |