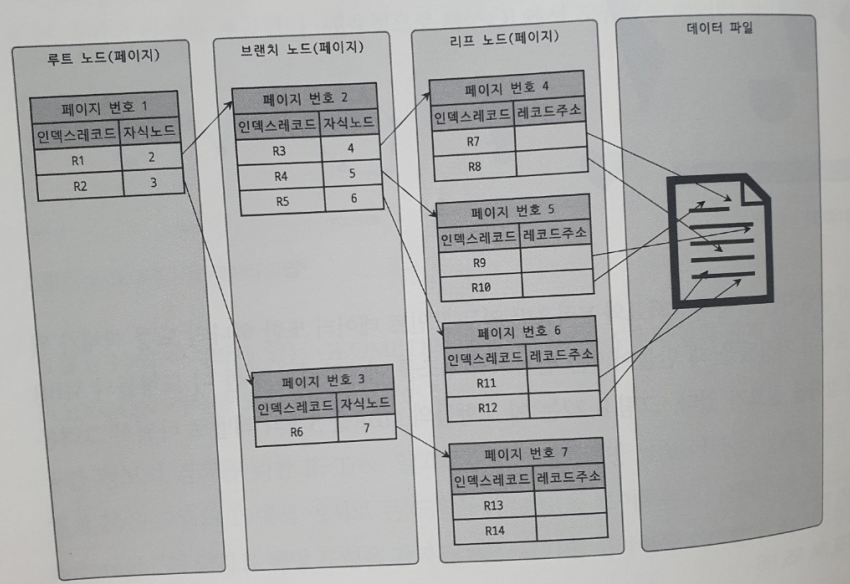
데이터를 안전하게 저장, 관리하고 효율적으로 조회하려면 옵티마이저가 어떻게 동작할지, 쿼리의 실행 계획에 대해 알아야한다.
실행 계획은 쿼리를 실행할때 EXPLAIN 키워드를 붙여서 실행하면 된다. 실행 계획도 그때그때 찾아보는 것이 좋을 것 같은데 자주 보이고 알면 좋은 부분만 정리해봤다.
실행 계획 결과는 기본적으로 테이블(json, tree 같은 포맷도 있다)로 여러 정보를 알려준다.

1. id
- 단위 select 쿼리(select 키워드 단위로 구분한 것)의 식별자로 테이블을 조인하면 조인되는 테이블의 개수만큼 실행 계획 레코드가 생기지만 같은 id 값을 가진다. (id 값이 같으면 조인된 경우)
- id가 테이블의 접근 순서를 의미하지는 않는다.
2. select_type
- 단위 select 쿼리가 어떤 타입의 쿼리인지 나타낸다.
- 서브쿼리를 사용하지 않는 단순 쿼리를 나타내는 SIMPLE, 서브 쿼리를 가지는 select 쿼리의 가장 바깥쪽에 있는 쿼리를 나타내는 PRIMARY 등의 키워드가 있다.
- DERIVED는 단위 SELECT 쿼리의 실행 결과로 메모리나 디스크에 임시 테이블(파생 테이블)을 생성하는 것을 의미하는데 주로 from절 서브쿼리를 사용하는 경우를 나타낸다. (성능상 주의깊게 볼 부분)
3. type
- MySQL 서버가 각 테이블을 어떤 방식으로 읽을지를 나타낸다.
- 주로 쓰이는 타입으로는 all < index < range < index_subquery < unique_subquery < ref < eq_ref < const 의 순서대로 빠른 순서를 보인다.
- const(Unique index scan)는 where절로 PK 또는 유니크 키로 1건만 조회하는 쿼리로 많이 사용하는 방식이다.
- eq_ref는 join에서 처음 읽은 테이블의 컬럼값을, 그 다음 읽어야 할 테이블의 PK나 유니크 키 컬럼의 검색 조건에 사용할 때 나타낸다.
- ref는 인덱스 종류와 관계없이 동등 조건으로 검색할 때를 나타낸다.
- index_subquery, unique_subquery는 where 조건절에서 사용되는 in(subquery) 형태의 쿼리를 나타낸다. MySQL8.0 버전은 in subquery 형태의 세미 조인의 최적화된 기능이 많이 도입 되어서 실제 테스트 해보니 ref로 실행 된다거나 하는 경우가 많았다. (책에서도 최적화 옵션을 비활성화 하고 테스트를 하고 있다)
- range는 인덱스 레인지 스캔 형태의 접근 방법으로 인덱스를 범위로 검색하는 경우 (<, >, IS NULL, BETWEEN, IN, LIKE)등의 연산자로 검색시 사용된다. 속도는 생각보다 낮지만 range로 조회만 하더라도 어느정도 최적의 성능이 보장된다고 한다.
- index는 인덱스를 처음부터 끝까지 읽는 인덱스 풀 스캔방식이다
- all은 풀 테이블 스캔 방식으로 InnoDB는 풀 스캔시 대량의 디스크 I/O를 유발하는 작업을 위해 한번에 많은 페이지를 읽어 들이는 기능(Read AHead)을 제공한다. 대용량 레코드 처리시 잘못 튜닝된 인덱스 쿼리보다는 풀 테이블 스캔이 더 나은 경우도 있다.
4. keys
- 실행 계획에서 사용하는 인덱스를 의미하며 쿼리를 튜닝할 때는 key 컬럼에 의도한 인덱스가 표시되는지 확인하는 것이 중요하다.
5. rows
- 얼마나 많은 레코드를 읽고 체크해야 하는지 예측한 레코드 건수를 의미한다.
- 스토리지 엔진이 가지고 있는 통계 정보를 참조해서 MySQL 옵티마이저가 산출해 낸 예상값이라서 정확하지는 않다.
6. filtered
- 필터링되고 남은 레코드의 비율을 의미한다.
7. extra
- 성능에 중요한 부분, 처리 방식등을 보여준다.
- Using where은 MySQL 엔진에서 스토리지 엔진으로부터 받은 데이터를 별도의 가공을 해서 필터링 작업을 처리한 경우에 나타난다. (검색 조건에 따라 스토리지 엔진에서 필터링을 할 수도, MySQL 엔진에서 필터링을 할 수도 있다.)
- Using index(커버링 인덱스)는 인덱스만 읽어서 쿼리를 처리할 수 있는 경우 나타난다. 인덱스를 이용해 처리하는 쿼리에서 가장 큰 부하는 인덱스 검색에서 일치하는 키 값들의 레코드를 읽기 위해 데이터 파일을 검색하는 작업이다. InnoDB의 세컨더리 인덱스는 데이터 레코드를 찾아가기 위한 논리 주소로 사용하기 위해 PK를 같이 저장하는데 이는 추가 컬럼을 하나 더 가지는 인덱스 효과도 얻을 수 있다. 하지만 너무 과도하게 인덱스 컬럼이 많아지면 메모리 낭비가 심해지고 레코드 저장, 변경 작업이 매우 느려질 수 있어서 주의해야한다.
-Using index condition는 (MySQL 5.6 버전부터) 인덱스를 범위 제한 조건으로 사용하지 못한다고 하더라도 인덱스에 포함된 컬럼의 조건이 있다면 모두 같이 모아서 스토리지 엔진으로 전달하는 것을 말한다. 만약 스토리지 엔진에서 범위 제한 조건으로 10000건을 조회해서 MySQL엔진으로 전달했는데 MySQL 엔진에서 체크 조건으로 1건만 필터링이 된다면 매우 비효율적이다.
- Using filesort는 order by를 처리하기 위해 적절한 인덱스를 이용하지 못해서 조회된 레코드를 메모리 버퍼에 복사해 다시 한번 정렬하는 경우를 말한다. (성능상 주의해야 될 부분)
explain analyze로 검색하면 쿼리의 실행 계획과 단계별 소요된 시간 정보를 확인할 수 있다.
- 들여쓰기가 같은 레벨에서는 상단 라인이 먼저 실행
- 들여쓰기가 다른 레벨에서는 가장 안쪽 라인이 먼저 실행
- actual time=0.007..0.009 : 첫번째 레코드를 가져오는 데 걸린 평균 시간(ms), 두번째는 마지막 레코드를 가져오는 데 걸린 평균 시간
- rows 처리한 레코드 건수
- loops 반복 횟수

실행 계획과 더불어 쿼리 시간을 측정하는 경우 주의할 부분이 있다.
MySQL 서버는 운영체제의 파일 시스템 관련 기능(시스템 콜)을 이용해 데이터 파일을 읽어온다. 그런데 일반적으로 대부분의 운영체제는 한 번 읽은 데이터는 운영체제가 관리하는 별도의 캐시 영역에 보관해 뒀다가 다시 해당 데이터가 요청되면 디스크를 읽지 않고 캐시의 내용을 바로 MySQL 서버로 반환한다. InnoDB 스토리지 엔진은 일반적으로 파일 시스템의 캐시나 버퍼를 거치지 않는 Direct I/O를 사용하므로 운영체제의 캐시가 큰 영향을 미치지 않는다.
하지만 MySQL 서버에서도 데이터 파일의 내용을 페이지 단위로 캐시하는 기능을 제공한다. InnoDB 스토리지 엔진이 관리하는 캐시를 버퍼 풀이라고 하는데 이는 인덱스 페이지는 물론이고 데이터 페이지까지 캐시하며, 쓰기 작업을 위한 버퍼링 작업까지 겸해서 처리한다.
MySQL 서버가 한번 시작되면 InnoDB의 버퍼 풀을 강제로 삭제할 수 있는 방법이 없다.
InnoDB 버퍼 풀은 MySQL 서버가 종료될 때 자동으로 덤프됐다가 다시 시작될 때 자동으로 적재된다.
- SET GLObAL innodb_buffer_pool_dump_at_shutdown=OFF
- SET GLObAL innodb_buffer_pool_load_at_startup=OFF
그래서 실제 쿼리의 성능 테스트를 MySQL 서버의 상태가 워밍업된 상태(캐시나 버퍼등의 데이터가 준비된 상태)로 할지 아니면 콜드 상태(캐시나 버퍼가 모두 초기화된 상태)에서 진행할지도 고려해야 한다. 일반적으로 쿼리의 성능 테스트는 워밍업된 상태를 가정하고 테스트한다고 한다.
MySQL의 버퍼 풀은 크기가 제한적이라서 쿼리에서 필요로 하는 데이터나 인덱스 페이지보다 크기가 작으면 플러시 작업과 캐시 작업이 반복해서 발생하므로 쿼리를 6~7번 정도 반복해서 실행한 후, 처음 한두 번의 결과는 버리고 나머지 결과의 평균값을 기준으로 비교하는 것이 좋다.
[참고]
RealMySQL 8.0
'데이터베이스' 카테고리의 다른 글
| [Mysql] 공간 데이터를 사용하는 방법(Real MySQL8.0) (0) | 2023.11.25 |
|---|---|
| [Real MySQL] 인덱스 (0) | 2023.04.16 |
| [Real MySQL] MySQL의 격리 수준 (0) | 2022.12.03 |
| [Real MySQL] MySQL 아키텍처 (0) | 2022.12.02 |
| [MyBatis] 마이바티스 스프링 연동 모듈 (0) | 2022.07.13 |